The project
The aim of this project is to perform some experimenta with graph embedding and link prediction starting from a raw dataset not yet semantically meaningful. It was developed as a final examination for the Knowledge Representation and Extraction course of the Digital Humanities and Digital Knowledge Master Degree at the University of Bologna held by professor Aldo Gangemi and Andrea Nuzzolese. The goal is to show that it is possible and fairly easy to transform non-linked data in a linked form, and that allows for many interesting options. DBpedia and Wikidata already offer a huge amount of entities related to music, but their properties are often very limited for musical records that are not much popular. Using a much wider dataset, which is more specialized in musical records, allow to make more interesting and accurate predictions. In the field of musical records, this could lead to a system which not only automatically predict the genres, descriptors and features of an album records, but also the probability of its likeness, taking into account the average scores given by the user.
In order to accomplish such task, the first step necessary was to gather a raw dataset that could be formalized in a set of triples. My aim was to work with a musical dataset regarding records and artists, so I extracted raw data from the RateYourMusic.com Website. RateYourMusic is a large musical database in which users are able to autonomously enter musical records and to label them according to various properties, such as its artist, its publication date, the musical genres, a range of descriptors and so on. For the purposes of this project, around 22000 musical records were extracted, ranging from the most popular to the lesser ones.
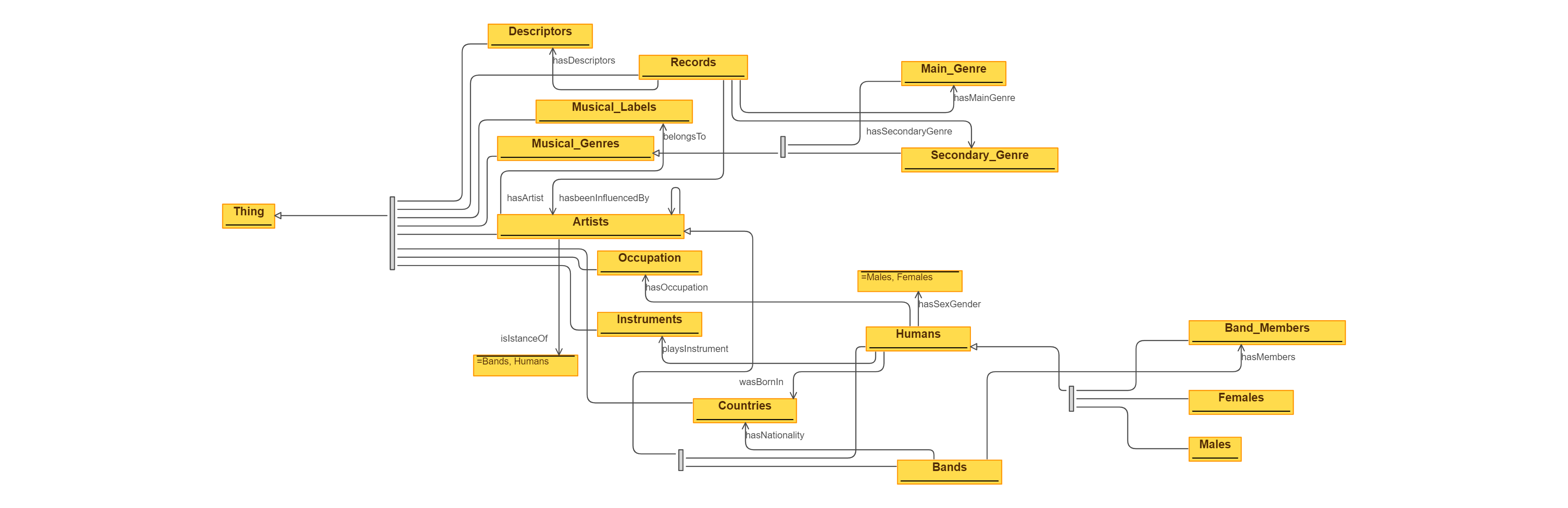
Then a simple and small ontology was developed using Protegé as a software. The ontology, which serves as a conceptual model, links an album record with its main properties, namely the artist that made the record, its main genre, its secondary genre, some descriptors and so on. I decided to implement my own ontology for the work in order to maintein the maximum flexibility; however, it could be useful and interesting to exploit already existing ontologies that deal with musical entities. Moreover, since one of the goal was also to align the dataset with Wikidata, the artist subclasses was subdivided in two different classes, i.e. humans (songwriters, performers, musicians, etc.) and musical groups. Those subclasses have properties as well, such as a birthplace for humans, a list of members for bands and so on. The list of properties for artists was completely arbitrary and it can be extended any time. You can download the Protegé file here.
From a practical point of view,Python was used in order to exploit the vast amount of libraries available for handling large datasets. Pandas was used to give a first look at the data, cleaning it a bit, eliminating duplicates and getting rid of some unnecessary properties. It was also important to align the entries with the already existing entries of a linked open dataset, such as DBPedia or Wikidata. Thus, a set of functions able to automatically extract information about a specific entity (using a SPARQL query) and put them in the main dataset were developed. Once the dataset was aligned (in this case with Wikidata), it became possible to serialize it as subject-predicate-object triples. Using an RDF library, it became possible to create a set of triples that linked every musical entity with its properties. Here you can see an example extracted from the graph using the Turtle syntax:

With the Turtle file, it became possible to make some experiment with graph embedding. For this task, two Python libraries were individuated:Pykeen and RDF2Vec. However, after an initial phase of testing, RDF2Vec was discarded due to the difficulties related to set up a proper work environment. Moreover, Pykeen offers a built-in function for link prediction, thus being much easier to set up for whom do not have prior knowledge in machine learning. For the training phase the dataset was automatically splatted in two (with a 80/20 proportion) and fed to the pipeline function without changing any of the default settings (except with the epoch number, which was set at 1500). You can download the results of the training here.
Finally, in order to get a more complete account of each record, a simple implementation of the nltk library was developed. This allows to get sentiment score (i.e. a positive, a neutral and a negative one) of each album based on the range of the descriptors. This score should represent the "mood" of the record, and it is not intended to express the value or the quality of it. For instance, a record could be labelled as mainly negative because its descriptors list includes terms such as "depressive", "melancholic" and so on. As it is often the case with the arts, negative feelings can be exploited to discuss important topics (e.g. depression) or to get rid of them.
All the data, including code and the trained model, can be found at the GitHub repository.